作业记录 – XML论文翻译
数据挖掘的质量数据与质量数据的数据挖掘
:一种基于XML方法的约束
Md. Sumon Shahriar
University of South Australia Adelaide, Australia
shamy022@students.unisa.edu.au
Sarawat Anam
Rajshahi University of Engineering and Technology
Rajshahi, Bangladesh
【摘要】
正如数据质量对数据挖掘的重要性,相对的,数据挖掘对测量数据的质量也是必要的。具体来说,在XML中,大量数据在网络中被存储和利用,因此数据质量问题的挖掘目的和使用据挖掘技术来测量数据质量就变得越来越必要。我们提出两个重要的相关问题:高品质的XML数据如何运用于数据挖掘和数据挖掘如何用于测量高品质XML数据。当我们解决这两个问题时,我们会考虑XML约束,因为XML约束可以用于测量XML数据的品质,也可以用于寻找一些XML数据挖掘的重要模式和关联规则。我们注意到XML约束可以在数据品质和XML数据挖掘中发挥重要的作用。我们提出理论框架而不是解决方案。我们的研究框架是针对集成XML数据的数据挖掘和数据质量的广泛任务。
【1.前言】
在任何数据模型中,高品质数据对数据挖掘都是非常重要的[1]。为了准确地在数据挖掘中找到有意义的模式和规则,数据必须完整、连贯且语意明确[2]。相反的,在这些规则和模式下,数据挖掘过程也可以用于测量一些数据的品质[9]。在测量数据品质时,完整性约束发挥着重要的作用。同样的,在数据挖掘过程中,约束的运用对寻找模式和规则也是十分有用的。
近年来,XML[13]在网络中被广泛运用于的数据表示和存储格式。因此,数据质量问题和数据挖掘流程的任务受到了数据库社区的重要关注[10,11,12]。我们考虑高品质的XML数据对于数据挖掘的必要性和数据挖掘对于高品质XML数据的重要性。我们根据XML约束来调查这些问题[7,8]。在XML中,XML键,XML功能依赖,XML外键,XML包含依赖和XML多值依赖是重要的完整性约束 [15,16,17,18,19,20,21,22,24,23,25]。关于这些约束有很多标准和提案,同时关于这些约束的研究也还在继续。
在一些XML数据品质测量中,运用了一些XML约束但对于XML约束的定义又是不同的。同样的,在一些XML数据挖掘中,也通过不同方法运用了一些XML约束。因此,我们在这给出一些例子来帮助研究问题。
我们首先给出一个数据质量(出于约束)如何影响XML中数据挖掘的例子。
例1.考虑图1中文件类型定义(DTD)D和图2中对应的一致的XML文件T。为简单起见,我们省略DTD中的#PCDATA类型。用DTD表示一个公司的用户信息。我们想知道数据中的下列信息:
“用户的职业分类,给用户的一些信用奖励。”
可以看到DTD的结构允许缺失值,如XML文件中的profession,因为profession元素的右上方有一个?符号。在XML文件T中,profession有一些缺失值。文件中缺失或者不完整的值会影响用户职业的寻找以及之后的分类。
现在我们的问题是如何限制这些不完整的数据。当然我们可以通过省略DTD中的?符号(就是说文件中的职业必须存在)或者运用完整性约束来解决这个问题。
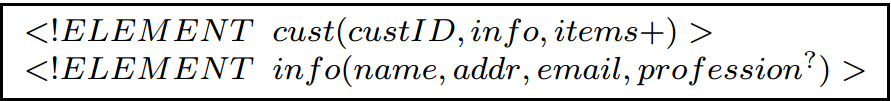
图1. XML DTD D
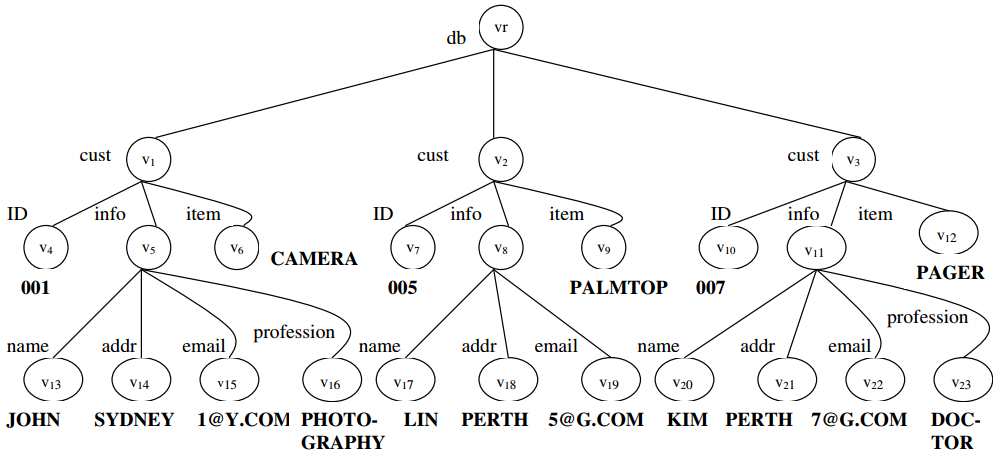
图2. 与D一致的XML Tree T
我们可以在DTD中强加一些约束。举个例子,custID是键,custID决定了profession。然后我们通过定义XML功能依赖来限制文件中profession值必须存在。因此强加约束可以帮助提升XML的数据品质和高效的数据挖掘。
观测1:数据品质可以通过XML约束判断,同时数据品质对数据挖掘也是十分必要的。
现在我们给出另一个例子,数据挖掘是怎么运用于XML中数据品质测量的。
例2.考虑图2中XML文件T是否符合图1中DTD D。我们想通过挖掘数据寻找到一些规则。比如我们想要下列关联规则:
“如果职业是摄影,他可能会买照相机。”
这种关联规则意味着“profession->item”,等式的左边是profession,等式的右边是item。如果我们观察XML文档,可以看到有一个缺失的左等式或者一位姓林的顾客的职业。缺失值或空值肯定会影响到挖掘的关联规则。然而,如果我们强加约束,类似“ID在功能上决定职业”,同时文档中必须存在职业,那么我们就不会得到职业的缺失值。注意,我们不能说“职业在功能上决定物品”,因为这种依赖关系在文件中是不正确的,例如,一个摄影师可以购买更多的物品,而不仅仅只是那一个。由此我们看到数据挖掘的约束是如何帮助检查数据质量的。
观测2:可以通过在数据挖掘中运用XML约束来决定一些数据的质量。
论文的组织结构如下。在下一节,我们给出了相关的研究问题。在第三节中,给出了基本定义。在第四节中,给出了提议的研究框架。在第五节中,我们给出了解决框架中研究问题的具体方法。在最后一节,我们用一些评论做总结。
【2.相关的工作】
数据品质和数据挖掘都是相关数据库中很好的学习主题[3,4,5,6,9,10]。在一些研究中运用完整性约束[2]。近年来,数据品质和半结构化的数据挖掘问题,特别是XML,都变得越来越重要[11,12]。然而数据品质和数据挖掘目的的XML完整性约束的利用和描述都有各自的限制。我们的研究接近一些前人探索过的工作[2,9,10]。但是我们研究的不同之处是在某种意义上,给数据品质和挖掘目的使用XML完整性约束,并且相对的运用数据挖掘技术测量XML中数据的质量。
【3.基本定义】
我们给出了剩余论文需要的一些基础定义和符号。
定义3.1(约束)约束,意味着键,功能依赖,包含依赖和外键。我们也想要约束模式和文档符合并满足约束。
定义3.2(数据品质)数据品质,意味着可以通过约束获取数据的完整性和一致性。
定义3.3(数据挖掘)我们用一些约束来定义数据挖掘,约束可以像为挖掘目的得关联规则一样被表示。
【4.提议的框架】
在这一节,我们展示为XML提议的框架。
定义4.1(XML约束框架)在XML中,约束框架由XML键,XML功能依赖,XML包含依赖和XML外键组成。有时,XML多值依赖也会被使用。
定义4.2(XML数据品质框架)我们在XML约束框架中使用约束来测量XML数据的品质。我们考虑数据的完整性和一致性。
定义4.3(XML数据挖掘框架)数据挖掘框架,就是为了挖掘目的在XML约束框架中使用约束。
【5.提议的方法】
以下是为了解决观测中遇到的问题而提出的方法。
5.1XML数据挖掘的质量数据
我们在图3中展示数据挖掘中为何需要质量数据。当我们讨论数据的质量问题时,我们使用约束来啊测量这些问题。
XML模式:我们考虑XML数据的XML模式。流行的XML模式定义是XML文档类型定义和XML模式。XML文档应该符合XML模式。
XML约束:重要的XML约束像XML键,XML功能依赖,XML多值依赖,XML包含依赖等可以被运用于测量XML数据质量中。当我们使用这些约束时,我们需要通过捕获XML数据的完整性和一致性来定义他们。同时,我们需要考虑XML约束定义包含在XML模式定义中。
XML数据挖掘的数据质量权值:在这个阶段,我们需要确定XML数据挖掘中数据质量的权值。这个阶段的结果将会被作为分析结果用作数据挖掘的数据质量的测量。
数据质量改进的重定义XML模式的反馈:这个阶段建议在XML数据挖掘目的中用一些约束改进数据质量来提升XML模式设计。

图3. 以XML数据挖掘的XML约束为特征的运用品质数据的处理流程
5.2XML质量数据的数据挖掘
我们讨论数据挖掘技术如何借助XML约束用于测量数据质量的流程。
在这种方法中,我们也使用XML模式及其一致性文档作为输入。但是为挖掘目的使用XML约束与为挖掘关联规则使用XML约束是不同的。
XML约束:我们用XML功能依赖,XML多值依赖等在XML文档中寻找一些有趣的模式和关联规则。
XML数据挖掘测量:在这个阶段,我们测量XML数据挖掘的参数,如维持和信任度。然后我们做一个数据挖掘技术如何有利于数据质量测量的分析结果。
挖掘XML数据中重定义XML约束的反馈:我们进一步评估XML约束是如何重定义XML模式来提高数据挖掘功能和探索XML数据质量。

图4. 为XML数据质量运用XML约束的数据挖掘处理流程
5.3迭代过程
我们讨论数据质量如何影响数据挖掘和如何将数据挖掘运用到数据质量测量中。如果观察图3和图4,我们就能发现两种方法都包含迭代反馈机制来帮助提升不管是数据质量还是XML中数据挖掘进程。这个增量和迭代过程帮助XML数据质量和数据挖掘。
【6.结论】
我们提出了一个新的数据质量和数据挖掘一起的XML数据模型的框架。尽管提出了这个框架,我们还是考虑XML约束。重要的XML约束以数据质量和数据挖掘进程为特征。这篇论文是一个理论框架,问题是被提出定义而不是被解决。我们认为提出的框架可以解决介绍中提到的观测的结果。
我们结合框架可以为XML数据集成,XML数据仓库,XML数据转换和XML数据仲裁工作。此外,这种方法在数据清洗有重要作用,反过来可以帮助数据质量和数据挖掘。
【引用】
[1] S. Abiteboul, R. Hull, and V. Vianu, Foundations of Databases, Addison-Wesley, 1995. [2] C. Gao, F. Wenfei, G. Floris, J. Xibei and M. Shuai, Improving data quality: consistency and accuracy, Proceedings of the 33rd international conference on Very large data bases, VLDB Endowment, Vienna, Austria, 2007. [3] P. Bohonnon, W. Fan, F. Geerts, X. Jia, A. Kementsietsidis, Conditional Functional Dependencies for Data Cleaning, ICDE, 2007. [4] W. Fan, F. Geerts, X. Jia, A. Kementsietsidis, Conditional Functional Dependencies for Capturing Data Inconsistencies, ACM TODS, 33(2), 2008. [5] W. Fan, F. Geerts, X. Jia, Semandaq: A Data Quality System Based On Conditional Functional Dependencies, VLDB, 2007. [6] W. Fan,Dependencies Revisited for Improving Data Quality(invited paper), ACM PODS, 2008. [7] W. Fan, XML Constraints: Specification, Analysis, and Applications, DEXA, 2005, pp.805-809. [8] P. Buneman, W. Fan, J. simeon and S. Weinstein,Constraints for Semistructured Data and XML, SIGMOD Record, 2001, pp. 47-54. [9] D. Luebbers, U. Grimmers and M. Jarke, Systematic Development of Data Mining-based Data Quality Tools, VLDB, 2003. [10] O. Hipp, U. Guntzer, and U. Grimmer,Data Quality Mining: Making a Virtue of Necessity, In Proc. of the 6th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery (DMKD), 2001. [11] A. G. Buchner, M. D. Mulvenna, S. S. Anand, M. Baumgarten and R. Bohm, Data Mining and XML: Current and Future Issues, WISE’00. [12] M.M. Khaing and N. Thein, An Efficient Association Rule Mining For XML Data, SICE-ICASE, 2006, pp. 5782-5786. [13] Tim Bray, Jean Paoli, and C. M. Sperberg-McQueen, Extensible Markup Language (XML) 1.0., World Wide Web Consortium (W3C), Feb 1998. [14] Henry S. Thompson, David Beech, Murray Maloney, and Noah Mendelsohn, XML Schema Part 1:Structures, W3C Working Draft, April 2000. [15] W. Fan and J. Simeon, Integrity constraints for XML, PODS, 2000, pp.23-34. [16] W. Fan and L. Libkin, On XML Integrity Constraints in the Presence of DTDs, Journal of the ACM, 2002, vol.49, pp. 368-406. [17] M. L. Lee, T. W. Ling, and W. L. Low, Designing Functional Dependencies for XML, EDBT, LNCS 2287, 2002, pp.124-141. [18] M. Arenas and L. Libkin, A Normal Form for XML documents, ACM PODS, 2002, pp. 85-96. [19] S. Hartmann and S. Link, More Functional Dependencies for XML,ADBIS, 2003, LNCS 2798, pp.355-369. [20] M. Vincent and J. Liu, Functional Dependencies for XML, APWEB, LNCS 2642, 2003. [21] J. Liu, M. Vincent and C. Liu, Local XML Functional Dependencies, WIDM, 2003, pp. 23-28. [22] M. Vincent, J. Liu and C. Liu, Strong Functional Dependencies and Their Application to Normal Forms in XML, ACM TODS, 2004, pp. 445-462. [23] J. Liu, M. Vincent and C. Liu, Functional Dependencies, From Relational to XML, PSI, LNCS 2890, 2003. [24] M. W. Vincent, J. Liu and M. Mohania, On the equivalence between FDs in XML and FDs in relations, Acta Informatica, 2007, pp.207-247. [25] P. Buneman, S. Davidson, W. Fan, C. Hara and W. C. Tang, Keys for XML, WWW10, 2001, pp.201-210.
【原文】
2008_IEEE_Quality Data for Data Mining and Data Mining for Quality Data A Constraint
About The Author
chongchongs
为成为一个独立游戏开发者而奋斗着~